【最初の注意】
本記事は、私が2002年当時に今はなき「XWIN II Web Page」で掲載したものを、基本的にそのままの形で再掲載したものです。では、どうぞ。
この前の記事「Dual Xeon 2.20GHz ベンチマーク編 II」
巻頭言 973 「Dual Xeon 2.20GHz ベンチマーク編 III」
驚いたことに物理的には2つのプロセッサと変わらないものの、Hyper-Threadingが有効でOS上では4つのプロセッサとして扱われているものと比較すると、実に45秒の短縮、率にして三割以上の性能アップとなったのである。
(前回までの続き)
これだけ見れば、確かにHyper-Threadingの効果は確認できる。だが、私にとって気になるのは、1つの物理プロセッサ内にある2つの論理プロセッサにスレッドが割り当てられた場合、どの程度パフォーマンスに影響が出るのかということがある。物理プロセッサと論理プロセッサの関係をもう一度示すと次のようになっている。

確かにこれで誤りはないのだが、いかんせん前回の巻頭言ではこのあたりがさっぱり意味不明というご意見を頂戴しているので、次回以降に予定している Hyper-Threadingテクノロジの解説まで待たず、ごくごく簡単にではあるが、Hyper-Threadingテクノロジについて、比喩を交えて説明しておこう。
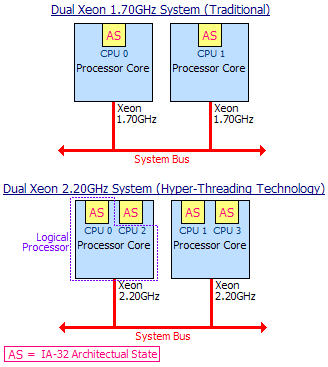
上に、Intel社の「Introduction to Hyper-Threading Technology」というドキュメントを参考にしたHyper-Threadingテクノロジの概念図を作成してみたので、これを見ながら話を進めよう。
図中の上に示したのは、2つのXeon 1.70GHzで構成されたシステムのプロセッサ周り、下は、2つのXeon 2.20GHzで構成されたシステムのプロセッサ周りである。大きな違いは、プロセッサ内のAS(IA-32 Architectual State)の個数が1つであるか2つであるかのみであり、これがHyper-Threadingテクノロジの肝である。IA-32 Architectual Stateとは何かというと、比喩的に言ってしまえば受付窓口のようなものである。
従来のプロセッサには命令の受け入れ窓口が一つしかなかった。これが二つに増えたことで、命令の受け入れ窓口をOSから見てプロセッサに見立てるというものが、論理(仮想)プロセッサである。OSから見れば、プロセッサとは命令受け入れ口に過ぎないのだから、それが本当に(物理的に)一つなのか二つなのかというのはまったくといっていいほど関係がない。
喩えて言うなら、今までは一つの店舗に一つのレジでやっていたが、品数が少なく簡単なものばかりであれば、店舗に働く従業員すべてに仕事が行き渡っていた。ところが、品数が増え、複雑な注文や注文がキャンセルされるようなことが出てくると、一つのレジでは仕事を処理しきれず、そのためにレジの仕事率を上げるなどしたが、今度はレジが誤るようになって来てしまい、店舗に働く従業員が暇をもてあますようになる等、処理能力を上げても非効率になり、とうとうライバル店の売上高に溝をあけられてしまった。それを改善するには、店舗の従業員を増やしたり、レジの回転率をこれ以上上げるというのは困難なので、今まで伝統的にレジを1つだったものを2つに増やし、遊んでいる従業員を少しでも働かせて効率をよくしようという方法を採用したのである。
喩え話で言えば、以上のようなものとなるだろうか。要するに、プロセッサの資源を増やして処理能力を上げるのではなく、プロセッサの資源をさらに有効活用して処理能力を上げようというアプローチなのである。
さて、喩え話が長くなってしまった。話を元に戻そう。
CPU 0とCPU 1を利用する場合と、CPU 0とCPU 2を利用する場合とでは、実質、物理プロセッサ2つと物理プロセッサ内の論理プロセッサ2つとの比較になるということである。上図からも明らかであるが、この両者が同じ結果を生むとは考えにくい。これを確認するため、これまでのテストと同様、Super πを用いて次のようなベンチマークテストを行ってみた。
これまでとの比較をする意味から、同時に実行するSuper πの数を4つと同じに揃え、2つずつ個別のCPUにスレッドを実行させるようにする。一つは、CPU 0とCPU 1にSuper πのスレッドを2つずつ持たせ、もう一つは、CPU 0とCPU 2に同じくSuper πのスレッドを2つずつ持たせることで違いを確認できるだろう。以下がその結果である。

最初は、CPU 0とCPU 1の組み合わせの結果である。この組み合わせは、物理プロセッサ2つであるので、前回テストしたHyper-Threadingを無効にした従来の Xeonと同じようなものといえるだろう。実行タイムは、CPU 0の側が2分55秒と2分56秒。CPU 1の側が両方とも2分56秒という結果になった。これは、プロセッサ数を2と制限(=Hyper-Threadingを無効)したものと比較すると、わずかながらであるが実行時間が3~5秒程度は短くなっている。これは、CPU使用率が51%と50%を超えていることからわかるように、Super π以外の実行スレッドがCPU 2やCPU 3で処理されることによるパフォーマンスアップである。
続いて最も興味深いテストとなるであろう、CPU 0とCPU 2の組み合わせの結果である。この組み合わせは、1つの物理プロセッサ内の2つの論理プロセッサで処理することになるので、Hyper- Threadingの弱点となり得るスレッドスケジューリングについての考察に役立つものとなるだろう。

パフォーマンスモニタの結果は、特に変わるものはないが、実行タイムは興味深い結果となった。CPU 0の側が4分8秒と4分11秒、CPU 2の側が4分7秒と4分10秒。面白いことに、常に同じCPUで実行する一方のスレッドの終了時間が長くなるのである。Super πの終了時間で計測すると、最後の方で一方のスレッドが終了するタイミングで処理が加速されてしまうため、4つの処理が並行して行われている19回目のループ終了時間で比較すると、その差はさらに強調されるものとなる。CPU 0の側は3分57秒と4分4秒、CPU 2の側は3分56秒と4分4秒。その差は実に7~8秒の開きを示したのである。
ちなみに4つのSuper πをすべてCPU 0に割り当てた結果は、実行タイムで5分33秒、5分36秒、5分37秒、5分37秒となっており、19回目のループ終了時間を見ると、4つともほぼ同じ時間であることから、明らかに違いがあることが確認できる。
ここで以上までの違いを明確にするため、表にして確認してみよう。

CPU 0~CPU 3に一つずつ実行スレッドを割り当てた場合
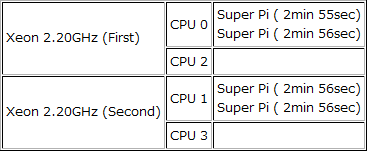
CPU 0とCPU 1に二つずつ実行スレッドを割り当てた場合
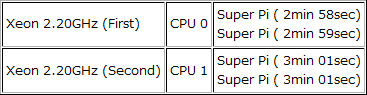
CPU 0とCPU 1に二つずつ実行スレッドを割り当てた場合(Hyper-ThreadingをOFF)
物理的にはSuper πを2つずつ割り当てた結果だが、それぞれまったく異なる結果を示している。うまくスレッドが割り当てられれば、従来と比較して30%以上の性能アップと言うIntel社のアナウンスは確かだといえるが、ベストの場合であるのはいうまでもない。これが物理プロセッサを基準とするのではなく、論理プロセッサを基準に採れば、CPU 0とCPU 2の組み合わせもある。
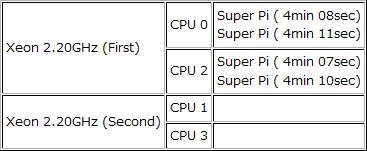
CPU 0とCPU 2に二つずつ実行スレッドを割り当てた場合
論理的に見れば2つのプロセッサに分散されているものの、物理的に見れば1つのプロセッサで実行されるこの組み合わせでは、先のいずれにも劣る結果となってしまう。もっとも、実際の局面においては実行スレッドとプロセッサを固定することはしないので(以前、Super πを一つだけ実行した例で示したように、単一スレッドであっても実行プロセッサは変化することが多い)、OSのスレッドスケジューリングが間抜けでない限りは、このような最悪な状況を迎えることはきわめて少ないということができるだろう。なお、同じ1つの物理プロセッサに割り当てられるものでも、論理プロセッサが1つに集中してしまうと、
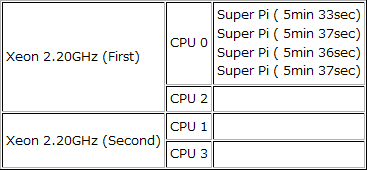
CPU 0に4つの実行スレッドを割り当てた場合
となるように、Hyper-Threadingの効果が発揮されていないわけではないことが確認できる。まさにこのことが、IA-32 Architectual State増設の効果(+OSのサポート)だといえよう。
さて、次回の予定だが、以上までの結果を踏まえてHyper-Threadingの有用性について、考えていく予定である。(2002/1/18)
【当時を思い起こして】
この時は、Super πをそれこそ何度行ったか。そして、何度も再起動を行ったことを思い出す。このPCはメモリチェックにやたらと時間のかかるものだったので、再起動作業をするだけで、それこそ何分も待たされるのだ(イメージ)。だが、そういった作業が苦とならなかったのは、Hyper-Threading Technologyの実態が見え隠れするような結果を見たからにほかならない。
コメント