【最初の注意】
本記事は、私が2002年当時に今はなき「XWIN II Web Page」で掲載したものを、基本的にそのままの形で再掲載したものです。では、どうぞ。
この前の記事「Dual Xeon 2.20GHz ベンチマーク編 I」
巻頭言 972 「Dual Xeon 2.20GHz ベンチマーク編 II」
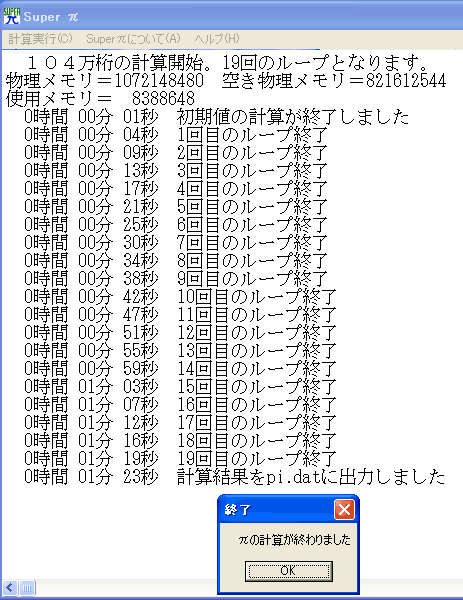
さて、前回予告どおり、Super π(以下、特に断りがなければ104万桁のテスト)を使いながら、Hyper-Threadingテクノロジの有効性を検証する。まず始めに、 Hyper-Threadingが有効で、他には特に何も設定しない状態で実行した結果から示していこう。
先に注意事項から述べておこう。Super πのベンチマークテストを行うにあたり、頻繁に設定を変える予定なので、その都度リセットを行う際、少しでも起動時間を節約するために通常2GBのメモリを半分の1GBに減らしている(具体的には8本のRIMMを4本に減らしている)。
さて、上がその結果であるが、Super πはいわゆるx87浮動小数点演算命令を利用しているので、Pentium IIIと比べてもFPU性能低下が著しいため、Athlonとはまったく勝負にならない(このあたりの理屈を抜きに、Super πでAthlonは速いと言うのは甚だわかっていないとしか言いようがない)のだが、2.20GHzというクロックでこの数字を叩き出している。Xeon 1.70GHzの時には、1分51秒だったので1分23秒ということは約28秒の短縮となる。約1.34倍の向上と計算上はなるので、クロック比よりもやや上回っているとなるだろう。
なお、Super πは、シングルスレッドアプリケーションプログラムなので、複数のCPUを割り当ててもまったく効果は変わらないが、OS(Windows XP)によって、デフォルトでは次のようにCPUは割り当てられている。
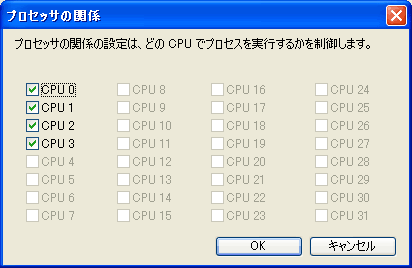
CPU 0、CPU 1、CPU 2、CPU 3と4つのCPUが割り当てられているが、無論、物理的にプロセッサ数は2つなので、残る2つは仮想(論理)プロセッサとなるが、この4つのCPUの関係は次のようになっている。

ただし、このように割り当てられてはいるが、CPU 0とCPU 2の間において、どちらかが物理プロセッサでもう一方が仮想(論理)プロセッサとなっているのではなく、一つのプロセッサの中に二つの処理可能状態(IA-32 Architectual State)を持つというものなので、両者間に優先順位や優位性を持つといったものはない。
さて、先にもふれたようにSuper πは、シングルスレッドアプリケーションプログラムであるので、デフォルトで4つのCPUを割り当てられていても、実際に使用されるCPUは1つである。ただし、CPU 0~CPU 3のいずれかを使うかは、OSによって委ねられている。タスクマネージャのパフォーマンスモニタに表示されるCPU使用率で、そのことを確認してみよう。

4つのCPUがあるため、1つあたりの使用率は最大で25%。つまり、スレッドが1つのSuper πのみがアクティブで実行されている状態では、CPU使用率の最大値は25%までとなる。4つのCPUでSuper πが実行されていることがモニタから読み取ることができるが、常に実行されているのは1つのCPUとなっていることがわかるだろう。
このように、OSがCPUの割り当てを行っているのだが、上の「プロセッサの関係」というもので、実行するCPUを特定してしまえば、OSはCPUのスケジューリングを行わず、常に指定されたCPUのみで実行するようになる。そこで、CPU 0~CPU 3に違いがあるかを確認するために、それぞれ一つだけSuper πの実行をするように制限したテストを行ってみよう。最初は、CPU 0のみにSuper πを割り当てた結果である(「プロセッサの関係」で、CPU 0のみにチェックを入れた場合)。

結果は1分25秒。パフォーマンスモニタを常時表示したまま計測している(以下、すべてのSuper πのベンチマーク結果は、パフォーマンスモニタ常時表示状態で実施)ため、約2秒ほど遅い結果となっているが、CPU使用率から自明のように、4つの CPUを割り当てた状態と基本的に変わらないものである。この後、引き続き、CPU 1~CPU 3についてそれぞれ行ってみたが、見事に結果は横並びの1分25秒となった。シングルスレッドにおいては、CPU 0~CPU 3の4つのCPUいずれもが等価であるということが確認できたわけである。
続いてのテストは、4つのCPUが同時に有効になるかを確認するため、Super πを4つ実行して、CPU 0~CPU 3のすべてに一つずつのSuper πを実行させることにした。もちろん、Super πはπの演算結果を書き出すため、それぞれ異なるフォルダに4つSuper πを用意して、それぞれ実行させなければならない点に注意が必要である。で、結果は次のとおりとなった。

ちょっと画面コピーをするタイミングが遅くなってしまったため、CPU使用率が0%の状態となってしまっているが、グラフをご覧いただければ明らかなように、4つのCPUがすべて使用されたため、実行中は100%となっていた。で、肝心の実行タイムは、4つとも、2分13秒から2分16秒の間である。時間にややばらつきがあるのは、4つのSuper πを手作業で順次実行したため、タイムラグが生ずることによる。当然、最初に実行したものはプロセスが一つしかないため、わずかだが演算効率が上がること。そして、終了が遅くなるものも最後はプロセスが一つになるので、これもわずかに演算効率が上がるために生ずるばらつきである。よって、この結果でも CPU 0~CPU 3は、いずれも等価であるということができるだろう。
ここで一旦、4つのCPUによるSuper πの結果は置いておいて、boot.iniに「/numproc=2」オプションを追加してCPUを2つに制限した状態で再起動した(=Hyper- Threadingを結果的にOFFにした)環境で、Super πを4つ実行させた結果を示しておこう。CPUが2つなので、1つのCPUには2つのSuper πを割り当てることになるが、物理的なプロセッサ単位としてはまったく同じであるので、Hyper-Threadingの有効性がどれほどのものかを垣間見ることができるはずである。では、その結果だ。

CPUの実行スレッドが1つだろうと2つだろうと、使用率そのものが変わるわけではない(使用率から仕事量が算出できないから)ので、このように2CPU か4CPUかの違いにしか見えないが、かかった時間は同じではなかった。実行タイムは、2分58秒から3分1秒の間であった。タイムにばらつきがあるのは先に示した理由と同じだが、驚いたことに物理的には2つのプロセッサと変わらないものの、Hyper-Threadingが有効でOS上では4つのプロセッサとして扱われているものと比較すると、実に45秒の短縮、率にして三割以上の性能アップとなったのである。
この項、つづく。(2002/1/17)
【当時を思い起こして】
ずいぶんとイメージ(画像)が切れっ端というか、余計なものを排除しているかが確認できるが、ファイルサイズを少しでも軽減しようという涙ぐましい配慮である。最近はほとんど気にすることはないといいつつも、さすがにデジカメのJPEGデータを何もせずにアップする気にはなれない(苦笑)。
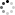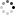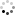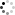
コメント